Flow to Flow communication
Introduction
One of the benefits of the Crosser solution is that you can deploy multiple flows (processes) into one existing container.
Due to that, you can add new use cases without influencing running processes at the edge, even without restarting or re-deploying the runtime (Docker Container or Windows Service).
This allows you to realize your use cases step by step and keep the processes isolated.
But you might also think about spreading use cases into different flows to have a clear seperation between process steps or even responsabilities within your team.
This article will describe some examples on how you can utilize flow to flow communication and use it to your advantage.
Flow to flow communication options
To understand how you can realize flow to flow communication, you need to know that the Crosser Edge Node comes with three additonal features, next to the processing engine.
MQTT Broker
The Crosser Edge Node comes with an integrated MQTT Broker which can be exposed to allow external client communication.
This allows you to publish data into the Crosser Edge Nodes' broker from external system like sensors, PLCs and many more.
The same principle can also be used if you want to interconnect flows. Since the broker is accessible from within the container, you do not even need to expose it to the outside world if you just want to realize flow to flow communication.
Therefore, you will find two modules in the module library which you can use to only connect to the integrated MQTT Broker.
MQTT Pub Broker: This module is designed to publish messages to the internal MQTT Broker topics
MQTT Sub Broker: This module is designed to subscribe to messages on the internal MQTT Broker topics.
Example
Lets assume you have your PLC connected and want to send transformed and aggregated data to your Azure IoT Hub.
Later on you decide to add another flow which should consume the same data but calculates KPIs or store the data in a on-premise database.
If you do changes to your KPI flow, you do not want to interrupt the data acquisition and transport to your Azure IoT Hub.
To do that, you can separate the flows. (flows are a bit simplified to illustrate the concept)
Flow A - Data acquisition and aggregation
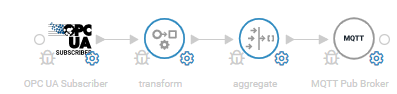
Flow B - Upload to Azure IoT Hub
Flow C - Bulk insert into MsSQL
Flow D - KPI generation
Merging this into the Crosser Edge Node detail view, it would look like this.
HTTP
As an alternative to MQTT you can use HTTP to send information from one flow to another.
Similar to MQTT, you can expose the Webserver to the outside world to allow external systems to push data into a flow.
Keep in mind that in order to send data to an HTTP endpoint, the endpoint needs to be opened by the webserver.
First thing you need to do is to open an HTTP endpoint using the HTTP Listener module and deploy the flow.
Lets assume you want to send information from an external system or flow to this endpoint (/mydata), you would do that by simply posting data to:
http://<my-node->/mydata:9090
Start of the flow in that case would be the HTTP Listener module with the following configuration.
(requested path must match the endpoint you want to post data to)
To post data to another flow, you can use the HTTP Request module and set the action to POST.
The basic idea is the same as for MQTT but keep in mind that the HTTP Endpoints are actually bounded to flows and not to the Crosser Edge Node.
In addition, we are only working with simple HTTP which means that you do not need to have a connection open between flows all the time.
This is especially helpful if this is simply restricted due to firewalls, or MQTT is overall not allowed since it can enable bi-directional communication.
Most of the time, customers use MQTT for flow to flow communication.
HTTP on the other hand comes with the big advantage, that it allows you to send in triggers from external systems with a simple post command.
Example
Lets assume you want to read certain data from your S7 PLC just in time, maybe due to some event.
You do not only want to read the data but also forward it to your KPI flow as soon as possible.
Your KPI flow though, is not hosted on the same Crosser Edge Node but on another Crosser Edge Node, which can only be reached through HTTP communication.
Your KPI flow though, is not hosted on the same Crosser Edge Node but on another Crosser Edge Node, which can only be reached through HTTP communication.
In that case, you can split your flows like below. (flows are a bit simplified to illustrate the concept)
Flow A - Trigger and data acquisition
Flow B - Listen to data and generate KPIs
Merging this into the Crosser Edge Node detail view, it would look like this.
Key/Value store
The Key/Value store is a great tool if you need to pic up certain data at some step in a flow.
While MQTT and HTTP push the data, you can decide where and when to read or write the data into the Key/Value store.
In general, you can have multiple Key/Value stores within one Crosser Edge Node. You can create new Key/Value stores with just adding a new name in the module configuration.
Overall you have three different Key/Value modules.
1. Key/Value Set
This module is used to create a Key/Value store and store the Key/Value pairs.
Important:
By default Key/Value stores are kept in memory. By enabling the flag 'persistent storage', you can write the Key/Value store to the local disk.
You can only access Key/Value stores which are created by other flows if the 'persistent storage'-flag is set to true.
2. Key/Value Get
This module allows you to pick up Values from a the Key/Value store.
3. Key/Value Delete
This module allows you to remove Values from a Key/Value store.
Example
Lets say you need to enrich streaming data with metadata which is held in a MsSQL database. The streaming data has a high frequency and you need to enrich every single message.
You could of course add the MsSQL Select module within your streaming flow, but this would put a lot of load on your database since you would execute the query for every message.
Usually the metadata does not change too often which makes it most likely sufficient, if you update it every now and then.
You can use the Key/Value store to store the metadata fetched from your MsSQL Server like once per hour and use the Key/Value Get module in your streaming flow instead.
Your flows could look like below. (flows are a bit simplified to illustrate the concept)
Flow A - Fetch metadata and save in Key/Value store
Flow B - Get streaming data and enrich with metadata
Merging this into the Crosser Edge Node detail view, it would look like this.
Related Articles
Securing HTTP and MQTT endpoints
By default the integrated HTTP server and MQTT broker in the Node use unencrypted communication without authentication. In this article we will explain how you can configure your nodes with encryption and/or authentication. TLS & Certificates To ...Node to Node communication
Introduction When talking about digitalization in the industry, security often comes up as one of the main concerns. Usually production environments are decoupled from other areas to prevent unauthorized actions. To realize this, a common practice is ...Flow sharing
June 30, 2022 Flow sharing It is now possible to decide who gets access to your flows. By default new flows will only be accessible to the creator (owner) of the flow. For others to see or change (depending on permissions) your flows you must ...The Flow Studio
The Flow Studio If you are using Flows built with previous versions of the Flow Studio, please check the "Using Flows built with the old Flow Studio" section below. The Flow Studio is the design tool you use to build and test flows. This is a drag & ...Flow Parameters
Flow Parameters Flow Parameters address the following two use cases: You want to use the same flow on multiple nodes, but some settings are different You use the same setting in multiple flows, e.g. credentials for access to some external service, ...